
I am currently a post-doctoral researcher at Software Institute, Nanjing University. In December 2025, I received my Ph.D. degree from School of Computer Science, Nanjing University under the supervision of Professor Qing Gu (顾庆) and Assistant Professor Zhiwei Jiang (蒋智威).
I have a broad interest in computer vision and deep learning, with a current focus on the controllable, consistent, and trustworthy visual generation in AIGC.
From Oct. 2024 to Oct. 2025, I was a visiting Ph.D. student at Singapore Management University, where I was guided by Associate Professor Qianru Sun and Assistant Professor Jiannan Li, with funding from the China Scholarship Council (CSC). From May 2023 to May 2024, I was a research intern at Tencent AI Lab, where I worked under the mentorship of Kuan Tian (田宽) and Jun Zhang (张军), concentrating on research in AIGC.
Research Experience
- 2026.01 – Present, Post-Doctoral Researcher,
Software Institute, Nanjing University, Nanjing, China.

- 2021.09 – 2025.12, Ph.D. Student,
School of Computer Science, Nanjing University, Nanjing, China.
- 2024.10 – 2025.10, Visiting Ph.D. Student,
School of Computing and Information Systems, Singapore Management University, Singapore.

- 2023.05 – 2024.05, Research Intern,
Tencent AI Lab, Technology & Engineering Group, Tencent, Shenzhen, China.

Honors and Awards
- Outstanding Graduate Student, Nanjing University, 2023.
- Huawei Scholarship, Nanjing University, 2023.
- Yingcai Scholarship, Nanjing University, 2021.
Selected Publications
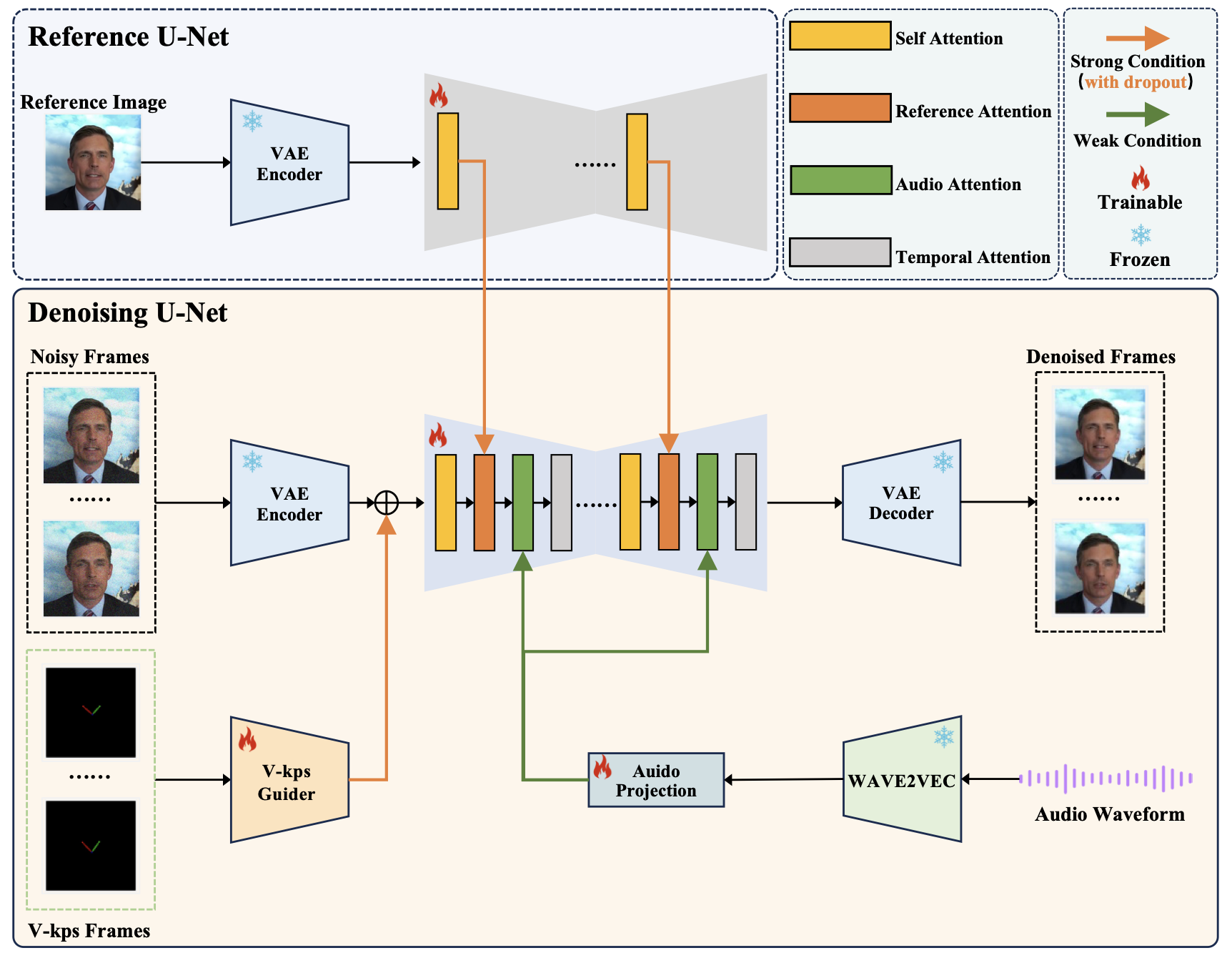
V-Express: Conditional Dropout for Progressive Training of Portrait Video Generation;
Cong Wang*,
Kuan Tian*,
Jun Zhang†,
Yonghang Guan,
Feng Luo,
Fei Shen,
Zhiwei Jiang†,
Qing Gu,
Xiao Han,
Wei Yang;
arXiv:2406.02511.
[code]
[project page]
[arXiv]
[models]
TL;DR: V-Express aims to generate a talking head video under the control of a reference image, an audio, and a sequence of V-Kps images.


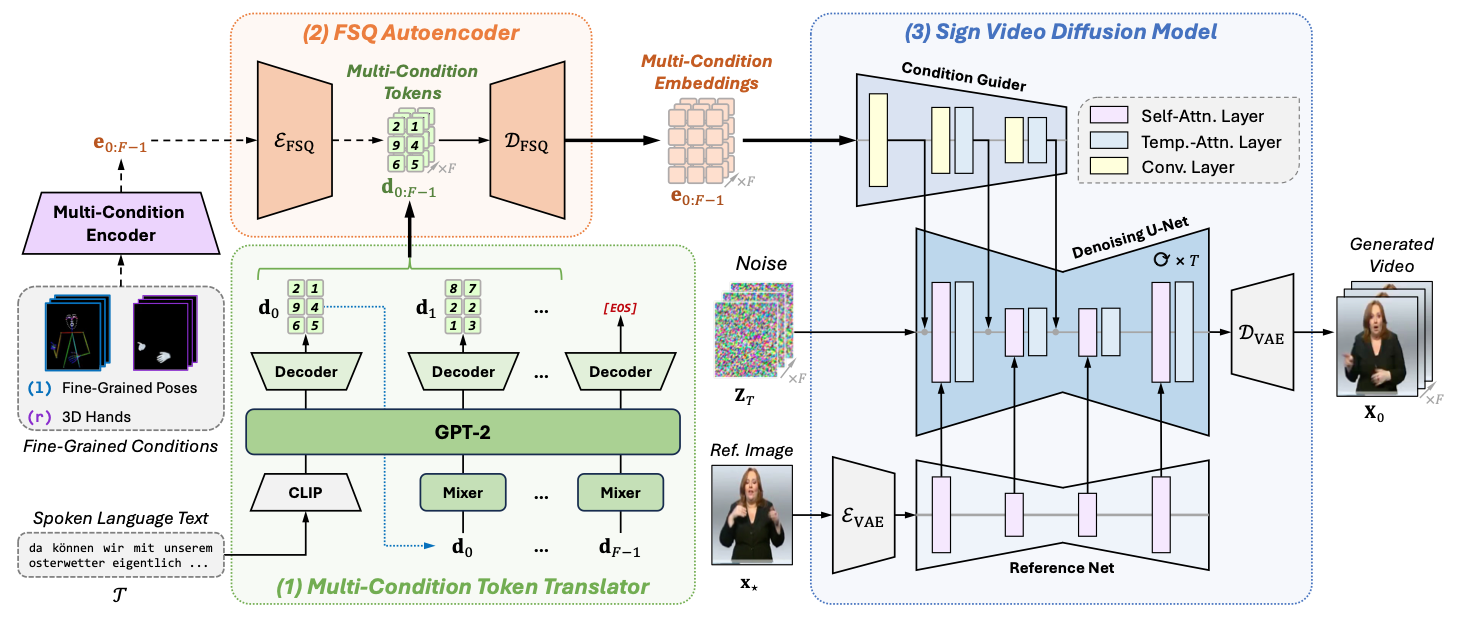
Advanced Sign Language Video Generation with Compressed and Quantized Multi-Condition Tokenization;
Cong Wang*,
Zexuan Deng*,
Zhiwei Jiang†,
Yafeng Yin†,
Fei Shen,
Zifeng Cheng,
Shiping Ge,
Shiwei Gan,
Qing Gu;
Annual Conference on Neural Information Processing Systems (NeurIPS), 2025.
[paper]
[code]
[model]
[poster]
[arXiv]
TL;DR: We propose SignViP, a novel SLVG framework that incorporates multiple fine-grained conditions for improved generation fidelity, which adopts a discrete tokenization paradigm to integrate and represent the conditions.
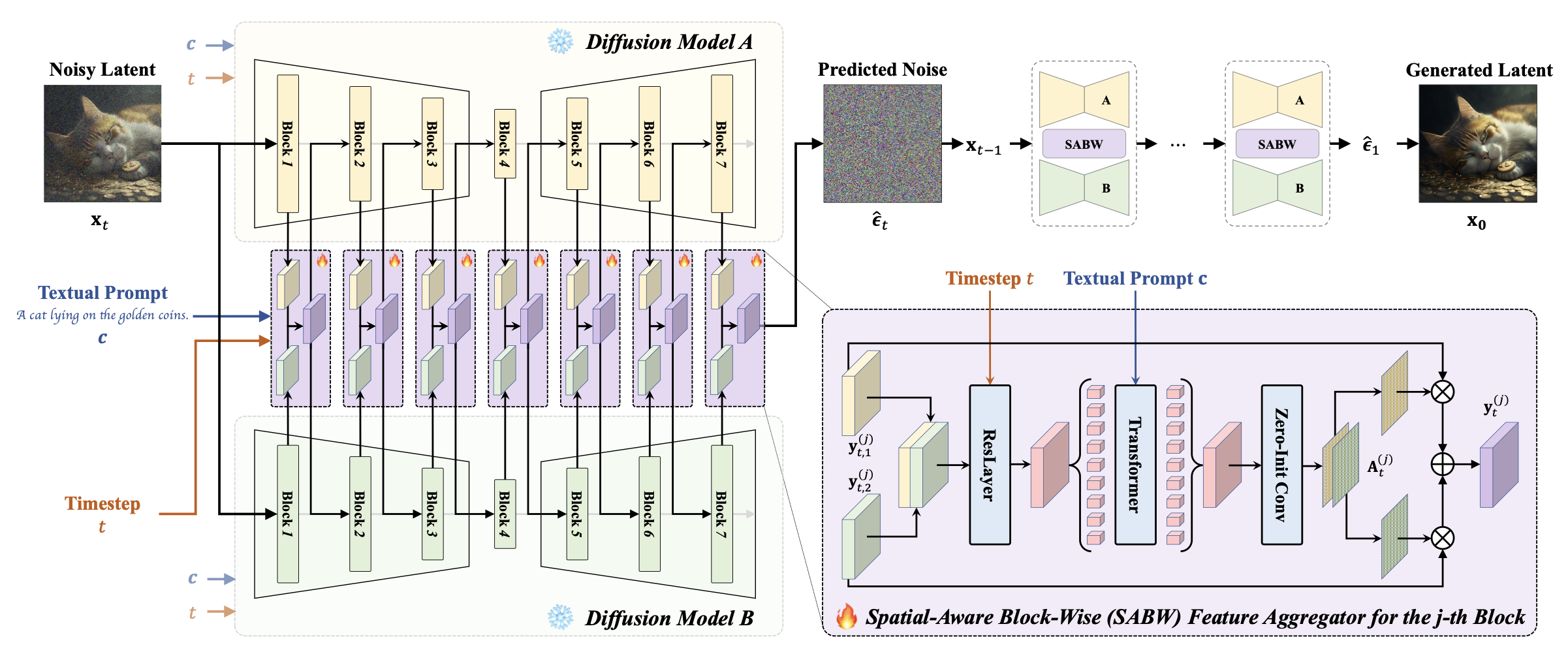
Ensembling Diffusion Models via Adaptive Feature Aggregation;
Cong Wang*,
Kuan Tian*,
Yonghang Guan,
Fei Shen,
Zhiwei Jiang†,
Qing Gu,
Jun Zhang†;
International Conference on Learning Representations (ICLR), 2025.
[paper]
[code]
[poster]
[arXiv]
TL;DR: We propose Adaptive Feature Aggregation (AFA) to ensemble multiple diffusion models dynamically based on different states like prompts, noises, and spatial locations.
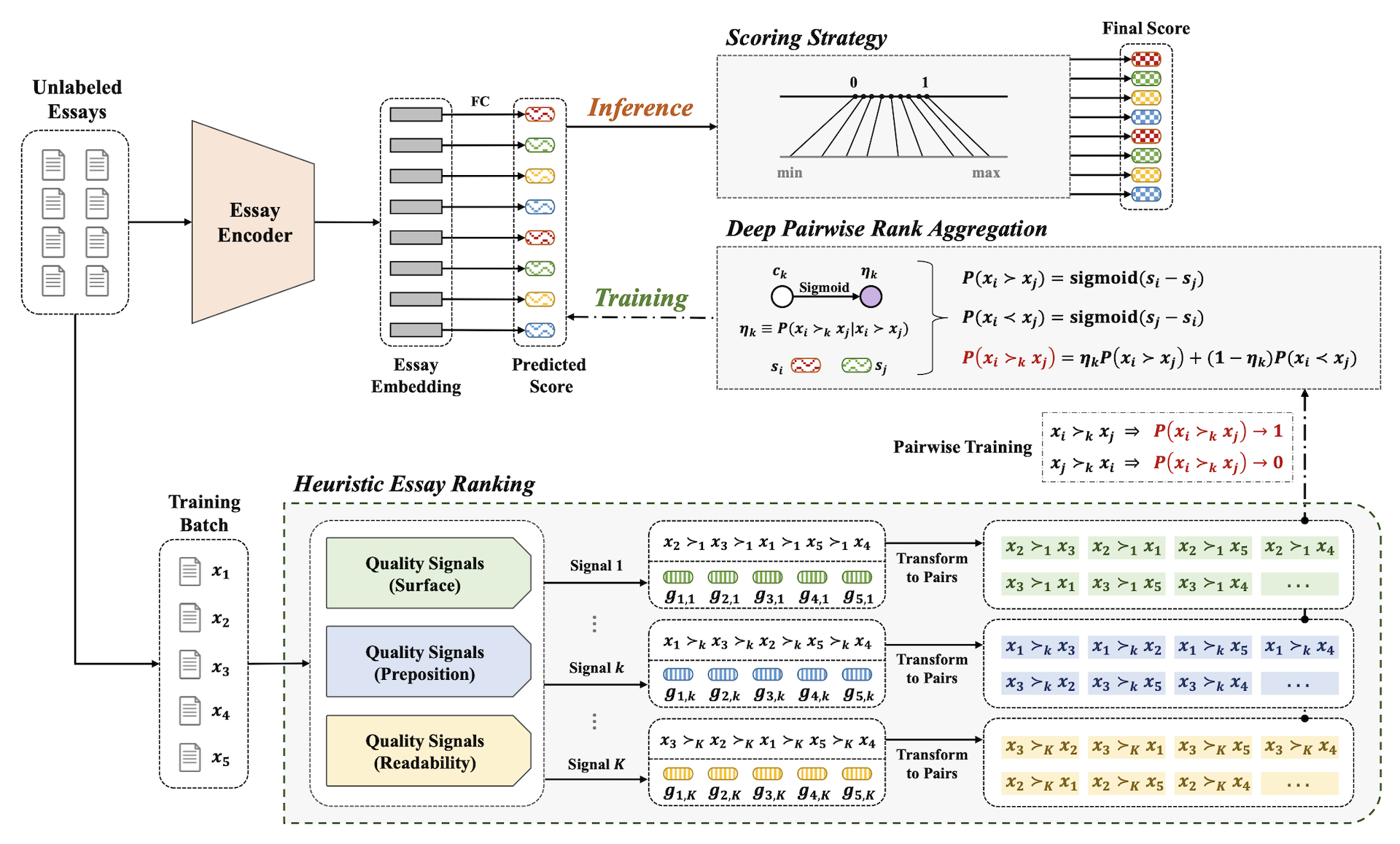
Aggregating Multiple Heuristic Signals as Supervision for Unsupervised Automated Essay Scoring;
Cong Wang,
Zhiwei Jiang†,
Yafeng Yin,
Zifeng Cheng,
Shiping Ge,
Qing Gu;
Annual Meeting of the Association for Computational Linguistics (ACL), 2023.
[paper]
[code]
[poster]
[slides]
[video]
TL;DR: We propose ULRA for unsupervised automated essay scoring, which utilizes multiple heuristic quality signals to train a neural network using Deep Pairwise Rank Aggregation loss.
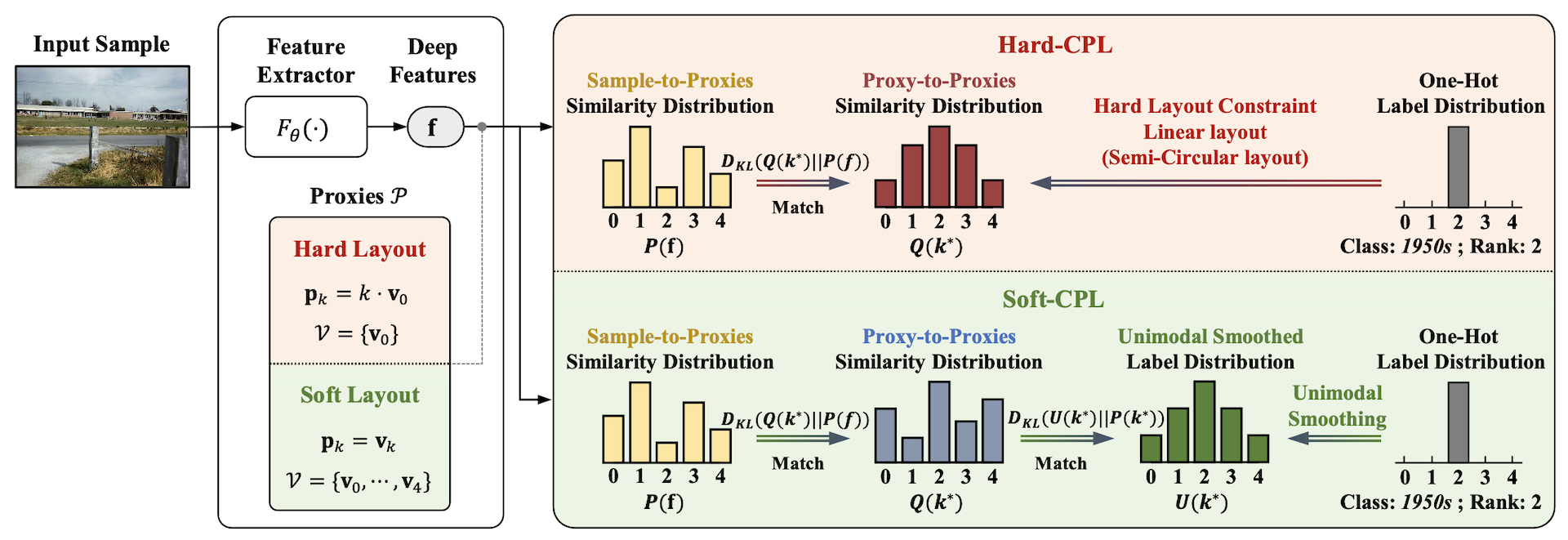
Controlling Class Layout for Deep Ordinal Classification via Constrained Proxies Learning;
Cong Wang,
Zhiwei Jiang†,
Yafeng Yin,
Zifeng Cheng,
Shiping Ge,
Qing Gu;
AAAI Conference on Artificial Intelligence (AAAI), 2023.
[paper]
[code]
[poster]
[slides]
[arXiv]
TL;DR: We propose Constrained Proxies Learning for deep ordinal classification, which learns proxies for ordinal classes and adjusts their layout in feature space to capture ordinal relationships.
* denotes equal contribution. † denotes the corresponding author.
All Publications
Preprints
- [P04] Where Culture Fades: Revealing the Cultural Gap in Text-to-Image Generation; Chuancheng Shi, Shangze Li, Shiming Guo, Simiao Xie, Wenhua Wu, Jingtong Dou, Chao Wu, Canran Xiao, Cong Wang, Zifeng Cheng, Fei Shen, Tat-Seng Chua.
- [P03] IMAGGarment: Fine-Grained Garment Generation for Controllable Fashion Design; Fei Shen, Jian Yu, Cong Wang, Xin Jiang, Xiaoyu Du, Jinhui Tang.
- [P02] A Debiased Nearest Neighbors Framework for Multi-Label Text Classification; Zifeng Cheng, Zhiwei Jiang, Yafeng Yin, Zhaoling Chen, Cong Wang, Shiping Ge, Qiguo Huang, Qing Gu.
- [P01] V-Express: Conditional Dropout for Progressive Training of Portrait Video Generation; Cong Wang, Kuan Tian, Jun Zhang, Yonghang Guan, Feng Luo, Fei Shen, Zhiwei Jiang, Qing Gu, Xiao Han, Wei Yang.
2026
- [C17] IMAGGarment+: Efficient Attribute-Wise Diffusion for Garment Generation; Jian Yu, Xiaoyu Du, Cong Wang, Yanpeng Sun, Hao Tang, Qing Guo, Fei Shen; AAAI.
- [C16] RegionMarker: A Region-Triggered Semantic Watermarking Framework for Embedding-as-a-Service Copyright Protection; Sunfan Yang, Zifeng Cheng, Zhiwei Jiang, Yafeng Yin, Cong Wang, Shiping Ge, Yuchen Fu, Qing Gu; AAAI.
2025
- [C15] Advanced Sign Language Video Generation with Compressed and Quantized Multi-Condition Tokenization; Cong Wang, Zexuan Deng, Zhiwei Jiang, Yafeng Yin, Fei Shen, Zifeng Cheng, Shiping Ge, Shiwei Gan, Qing Gu; NeurIPS.
- [C14] Steering When Necessary: Flexible Steering Large Language Models with Backtracking; Zifeng Cheng, Jinwei Gan, Zhiwei Jiang, Cong Wang, Yafeng Yin, Xiang Luo, Yuchen Fu, Qing Gu; NeurIPS.
- [C13] Contrastive Prompting Enhances Sentence Embeddings in LLMs through Inference-Time Steering; Zifeng Cheng, Zhonghui Wang, Yuchen Fu, Zhiwei Jiang, Yafeng Yin, Cong Wang, Qing Gu; ACL.
- [C12] Multi-Prompting Decoder Helps Better Language Understanding; Zifeng Cheng, Z. Chen, Zhiwei Jiang, Yafeng Yin, Cong Wang, Shiping Ge, Qing Gu; ACL Findings.
- [C11] Long-Term TalkingFace Generation via Motion-Prior Conditional Diffusion Model; Fei Shen, Cong Wang, Junyao Gao, Qin Guo, Jisheng Dang, Jinhui Tang, Tat-Seng Chua; ICML.
- [J03] Fine-Grained Alignment Network for Zero-Shot Cross-Modal Retrieval; Shiping Ge, Zhiwei Jiang, Yafeng Yin, Cong Wang, Zifeng Cheng, Qing Gu; TOMM.
- [C10] Ensembling Diffusion Models via Adaptive Feature Aggregation; Cong Wang, Kuan Tian, Yonghang Guan, Fei Shen, Zhiwei Jiang, Qing Gu, Jun Zhang; ICLR.
- [C09] IMAGDressing-v1: Customizable Virtual Dressing; Fei Shen, Xin Jiang, Xin He, Hu Ye, Cong Wang, Xiaoyu Du, Zechao Li, Jinhui Tang; AAAI.
- [C08] Boosting Consistency in Story Visualization with Rich-Contextual Conditional Diffusion Models; Fei Shen, Hu Ye, Sibo Liu, Jun Zhang, Cong Wang, Xiao Han, Wei Yang; AAAI.
2024
- [C07] AP-Adapter: Improving Generalization of Automatic Prompts on Unseen Text-to-Image Diffusion Models; Yuchen Fu, Zhiwei Jiang, Yuliang Liu, Cong Wang, Zexuan Deng, Zhaoling Chen, Qing Gu; NeurIPS.
- [C06] Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models; Fei Shen, Hu Ye, Jun Zhang, Cong Wang, Xiao Han, Wei Yang; ICLR.
2023
- [C05] Learning Event-Specific Localization Preferences for Audio-Visual Event Localization; Shiping Ge, Zhiwei Jiang, Yafeng Yin, Cong Wang, Zifeng Cheng, Qing Gu; MM.
- [C04] Aggregating Multiple Heuristic Signals as Supervision for Unsupervised Automated Essay Scoring; Cong Wang, Zhiwei Jiang, Yafeng Yin, Zifeng Cheng, Shiping Ge, Qing Gu; ACL.
- [C03] Unsupervised Readability Assessment via Learning from Weak Readability Signals; Yuliang Liu, Zhiwei Jiang, Yafeng Yin, Cong Wang, Shen Chen, Zhaoling Chen, Qing Gu; SIGIR.
- [C02] Learning Robust Multi-Modal Representation for Multi-Label Emotion Recognition via Adversarial Masking and Perturbation; Shiping Ge, Zhiwei Jiang, Zifeng Cheng, Cong Wang, Yafeng Yin, Qing Gu; WWW.
- [C01] Controlling Class Layout for Deep Ordinal Classification via Constrained Proxies Learning; Cong Wang, Zhiwei Jiang, Yafeng Yin, Zifeng Cheng, Shiping Ge, Qing Gu; AAAI.
2022
- [J02] A Consistent Dual-MRC Framework for Emotion-Cause Pair Extraction; Zifeng Cheng, Zhiwei Jiang, Yafeng Yin, Cong Wang, Shiping Ge, Qing Gu; TOIS.
- [J01] Learning to Classify Open Intent via Soft Labeling and Manifold Mixup; Zifeng Cheng, Zhiwei Jiang, Yafeng Yin, Cong Wang, Qing Gu; TASLP.
Students
- Huiyi Wang (Ph.D. Student, 2025, co-supervised with Qing Gu & Zhiwei Jiang)
- Haiyu Wu (Master Student, 2025, co-supervised with Qing Gu & Zhiwei Jiang)
- Zexuan Deng (Master Student, 2023, co-supervised with Qing Gu & Zhiwei Jiang): NeurIPS x 1
Academic Services
- Journal Reviewer: TNNLS, TOMM;
- Conference Reviewer: ECCV (26), ACL ARR (Jan. 26, Oct. 25, Jul. 25, May 25, Feb. 25), ICML (26), CVPR (26), ICLR (26, 25), AAAI (26), NeurIPS (25), MM (25, 24, 23), ICCV (25), ICML (25), IJCAI (25), ICIC (24), EMNLP (23).